
VEGA
Commissioned as the primary supercomputer system of the Slovenian national research infrastructures upgrade project “HPC RIVR” and delivered as the first of EuroHPC Joint Undertaking systems, Vega is hosted at the Institute of Information Science – IZUM in Maribor. It increases the computing capacity in Slovenia and the European Union as a whole and helps researchers, as well as other users in the public and private sector.
HPC Vega is a driving force in innovation, helping Europe to compete globally in strategic areas, such as artificial intelligence, advanced data analytics (HPDA), personalized medicine, bioengineering, fighting climate change, and the development of medicine and new materials. The main characteristics of HPC Vega are described below:

With 960 CPU nodes (overall 1920 CPUs AMD Epyc 7H12 – 122000 cores) and 60 GPU nodes (overall 240 GPUs NVidia A100) the sustained performance of HPC Vega is 6,9 PFLOPS (peak performance is 10.1 PFLOPS).
Power supply and Cooling infrastructure for HPC Vega is divided into several areas. One 1.6‑MVA 10k/400V transformer is installed in a separate facility room and the whole facility is backed up by a 820-kVA diesel generator.
The company Atos supplied and installed 12 liquid-cooled BullSequana racks for compute nodes in the RIVR1 system room. Compute part in RIVR1 is backed-up with UPS autonomy of a few minutes to enable clean shutdown procedure. Adiabatic cooling system is installed for warm-water regime with inlet 35°C and outlet 50°C enabling free cooling for 90% of time and is efficient up to outdoor temperature of 33°C. This system is placed on the roof of the IZUM building and chiller for RIVR1 is placed in the cellar. This system can provide cooling up to 880kW of heat loses in RIVR1.
The RIVR2 room is equipped with classical in-row air conditioning. 7 standard racks are installed for 61 storage Ceph nodes, 10 DDN storage nodes, 30 virtualization/service nodes and 8 login nodes. One wider rack is for communication equipment. Routers are placed in a separate telecommunication system room. Power consumption of the RIVR2 system area is limited to 110kW. In the case of power outages, only the RIVR2 room is supplied with power from UPS and the diesel generator. In RIVR2, there is a redundant cooling system with standard cold-water regime.
System overview
Network topology is shown below:
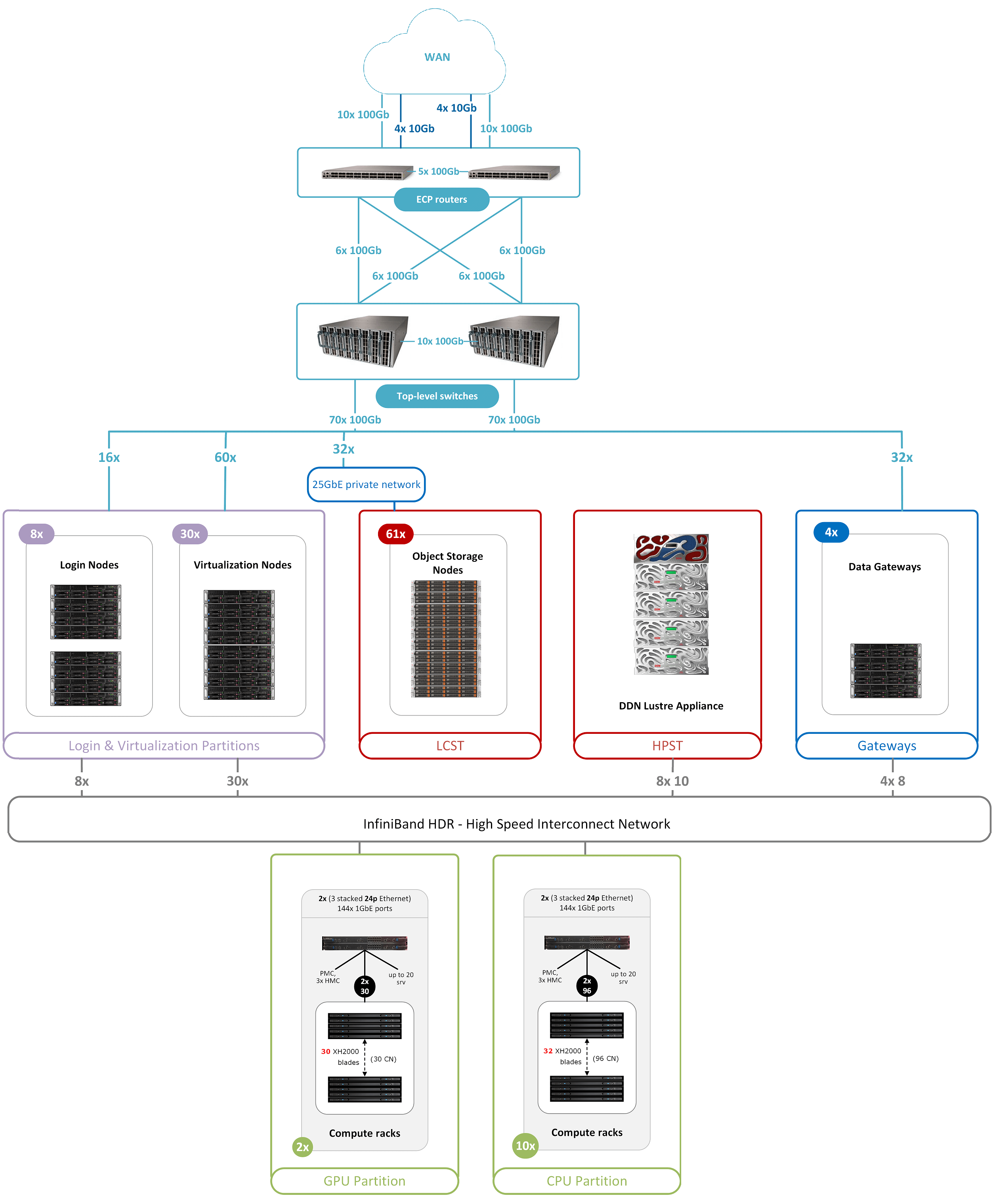
Connectivity and network infrastructure
HPC Vega WAN connectivity to the ARNES backbone network is redundant and provided by the CPE routers. The main goals are to provide sufficient bandwidth capabilities to other data centres and supercomputers within the SLING network, EU, and worldwide for large data transfers and quality, reliable and secure connectivity for all user communities.
Top-level ethernet network consists of two CPE routers Cisco Nexus N3K – C3636C-R used for redundant connection of 5 x 100GbE to WAN to backbone (to be provided by the end of 2021) and two top-level ethernet switches Cisco Nexus N3K – C3408-S (192 ports 100GE activated) used to provide redundant connection for nodes in login, virtualisation, and service partitions and for storage subsystems High-Performance Storage Tier (HPST) and Large-Capacity Storage Tier (LCST).
Top Management Network consist of two Mellanox 2410 switches (per switch 48 x 10GbE ports). In/Out of Band Management Network consist of several Mellanox 4610 switches (per switch 48 x 1GbE + 2 x 10GbE ports) and Rack Management Network consist of BullSequana integrated switches WELB (sWitch Ethernet Leaf Board) with three 24-port Ethernet switch instances and one Ethernet Management Controller (EMC).
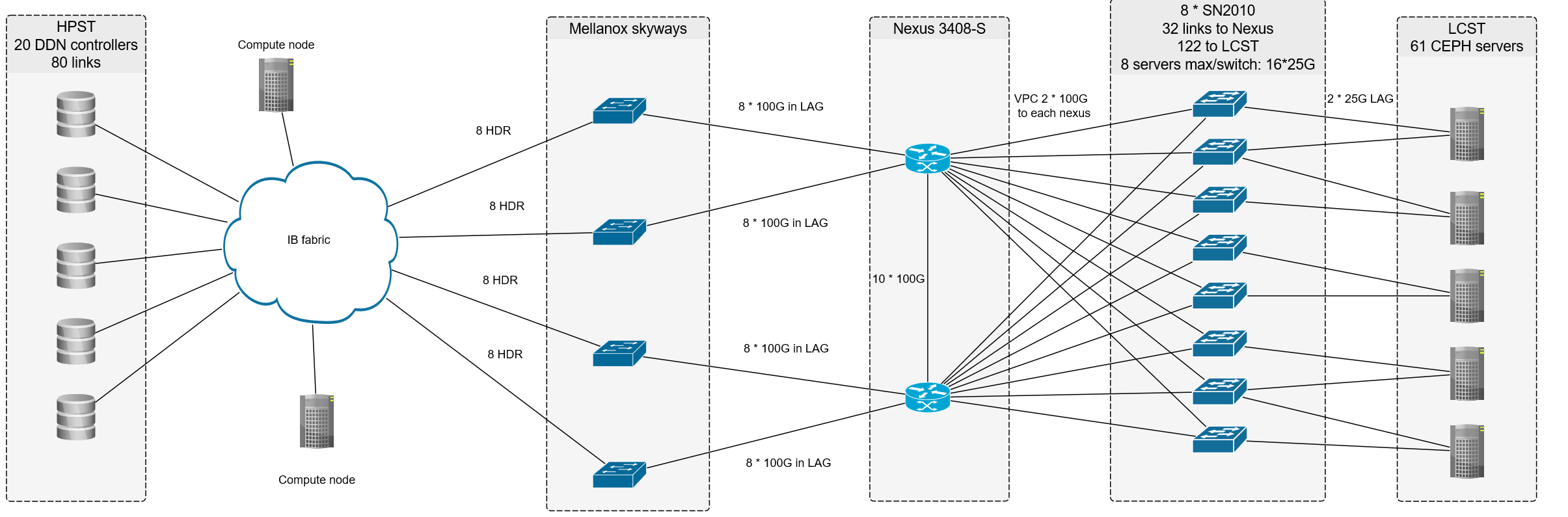
Interconnect and data gateways
Interconnect Network consist of 68 x 40-port Mellanox HDR switch with Dragonfly+ topology:

All 960 compute, 60 GPU, 8 login, 30 virtualization, 10 HPST storage nodes and 8 Skyway Gateways are connected with Mellanox ConnectX-6 (single or dual port).
Four NVIDIA (Mellanox) Skyway Gateway GA100 IP/Data Gateways with 8 connections on each side are used to route IP traffic between Infiniband on the compute cluster and LCST, based on Ceph. With this approach, compute nodes have access to the internet, so interaction between other data sources through secure networks such as LCHONE can be done.
Computing partitions
CPU partition consist of 10 BullSequana XH2000 DLC racks, with:
768 standard compute nodes (within 256 blades), each node with:
- 2 CPUs AMD EPYC Rome 7H12 (64c, 2.6GHz, 280W), 256GB of RAM DDR4‑3200, 1 x HDR100 single port mezzanine, 1 x local 1.92TB M.2 SSD
192 large memory compute nodes (within 64 blades), each node with:
- 2 CPUs AMD EPYC Rome (64c, 2.6GHz, 280W), 1TB of RAM DDR4-3200, 1 x HDR100 single port mezzanine 1 x 1.92TB M.2 SSD
GPU partition consist of 2 BullSequana XH2000 DLC racks, with:
60 GPU nodes (60 blades), each node with:
- 2 CPUs AMD EPYC Rome (64c, 2.6GHz, 280W), 512 GB of RAM DDR4-3200, local 1.92 TB M.2 SSD
- 4 x NVIDIA Ampere A100 PCIe GPU (3456 FP64 CUDA cores, 432 Tensor cores, Peak FP64 9.7 TFLOPS, FP64 Tensor Core 19.5 TFLOPS), each with 40 GB HBM2 and max. TDP 400W
HPC Vega consist of 1020 compute nodes with at least 256 GB of RAM, a total of 130,560 CPU cores. Sustained performance on all CPUs is 3.8 PFLOPS. 240 GPU accelerators with a total of 829,440 FP64 CUDA cores and 103,680 Tensor cores perform 3.1 PFLOPS.
High-performance storage tier (HPST) – Lustre
HPST contains 10 DDN ES400NVX Building Blocks, each consists of:
- The ES400NVX base enclosure with 1+1 redundant storage controllers and fully redundant IO-paths to the storage devices, redundant Fans and Power Supplies
- 23 x 6.4TB NVMe devices (DWPD=3), formatted in 2 x 10/0 flash pools
- 1 x NVMe device as HotSpare media, 8 x InfiniBand HDR100 frontend ports
- 4 embedded virtual machines (VM) to run the Lustre vOSS and vMDS with 1 OST and 1 MDT per VM.
The building block provides 111TB of formattable capacity. After applying filesystem overhead, the usable Lustre capacity is around 1PByte for data and a maximum of 5 billion inodes in the system. Flash-based performance (MAX read and write) is more than 400GB/s. HPST based on Lustre represents disk capacities for scratch space for I/O intensive applications and large scale jobs.
Large-capacity storage tier (LCST) – Ceph
LCST contains 61 Supermicro SuperStorage 6029P-E1CR24L servers, each consists of:
- 2 x CPU Intel Xeon Silver 4214R (12c, 2.4GHz, 100W), RAM 256GB DDR4 2933
- 2 x 6.4TB NVMe system disk and 24 x 16TB 3.5″ SATA3 7.2K RPM data disk
- 2 x 25GbE SFP28 to private internal network.
2 x NVMe SSDs per server provide a 12.8TB raw NVMe capacity in total per OSD node. Each server contains 384TB hard disk drive capacity and all together at least 19PB of usable Ceph storage (with 16+3 erasure coded pools). Internal Ceph Network contains 8 Mellanox SN2010 switches, each 18 x 25GbE + 4 x 100GbE ports.
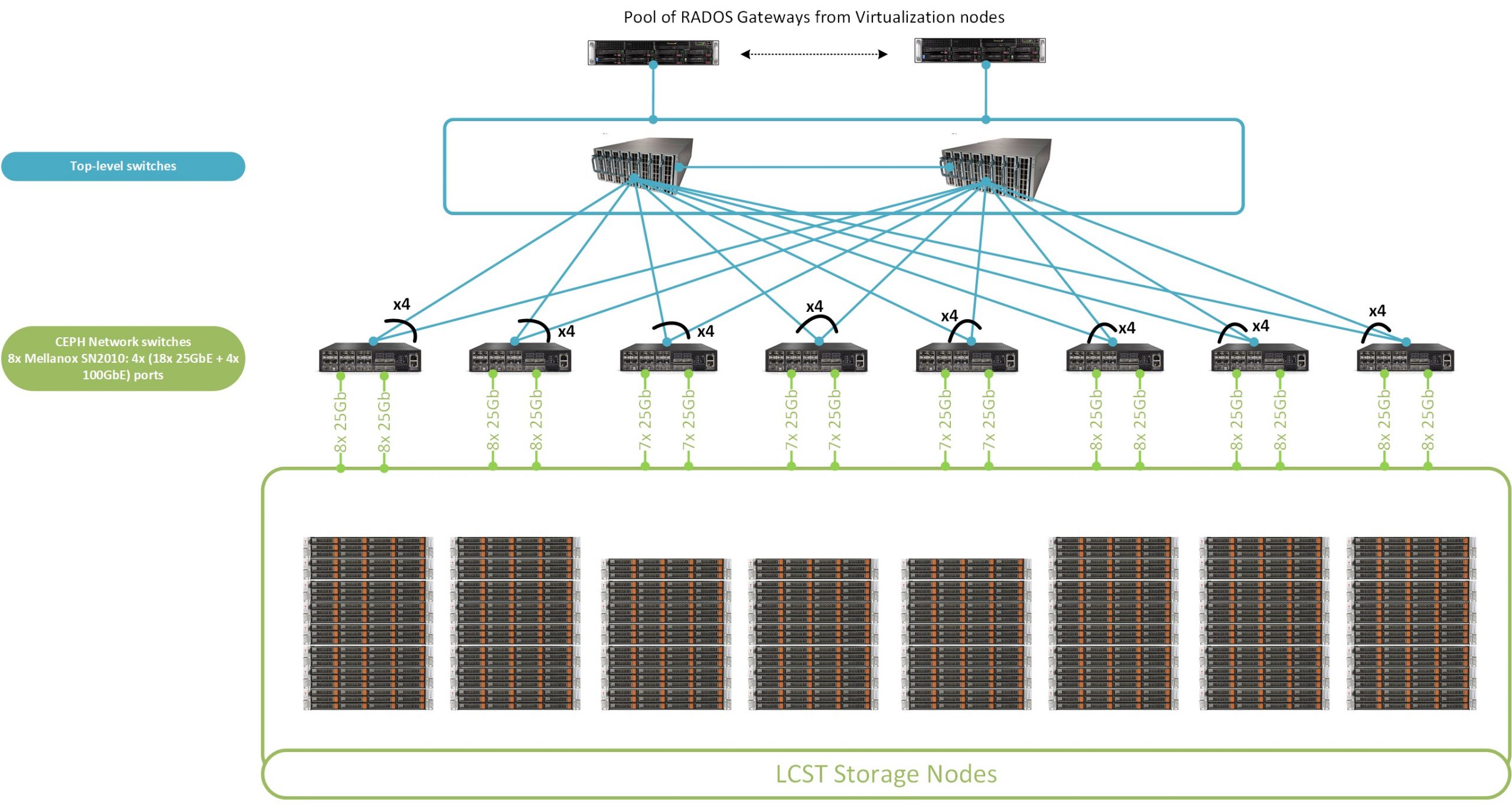
Ceph storage performance is over 200GB/s. LCST based on Ceph represents disk capacities for:
- long-term services (system services and cloud virtualization)
- user home directories (100GB defaults per user account)
- project group shared space and long-term scientific data repositories
Login nodes
4 Atos BullSequana X430-A5 CPU login nodes consist of:
- 2 x AMD EPYC 7H12 (same as on CPU partition),
- 256GB of RAM DDR4 3200, 2 x local 7.6TB U.2 SSD
- 1 x 100GbE DP ConnectX5, 1 x 100Gb IB HDR ConnectX-6 SP.
4 Atos BullSequana X430-A5 GPU login nodes consist of:
- 1 x PCIe GPU NVIDIA Ampere A100 with 40GB (same model as on GPU partition)
- 2 x AMD EPYC 7452 (32c, 2.35GHz, 155W)
- 256GB of RAM DDR4 3200, 2 x local 7.6TB U.2 SSD
- 1 x 100GbE DP ConnectX5 and 1 x 100Gb IB HDR ConnectX-6 SP.
On Login nodes users can test their appliactions on the same CPUs and GPUs as they are used on CPU and GPU partitions.
Virtualization and Service partition
30 Atos BullSequana X430-A5 virtualization nodes consist of:
- 2 x AMD EPYC 7502 (32c, 2.5GHZ, 180W)
- 512GB of RAM DDR4 3200
- 2 x 7.6TB U.2 SSD
- 1 x 100GbE DP ConnectX5 and 1 x 100Gb IB HDR ConnectX-6 SP
Virtualization and service partition is used for general purpose long term services, administrative tasks, and tasks that do not correspond to the compute, GPU, and login partitions. They are mainly used for system services and cloud infrastructure.
Software environment
- Atos System software: Smart Management Center, Bull Energy Optimizer, Performance Toolkit, IO Instrumentation
- Monitoring, alerting: DDN Insight Monitoring Software & ExaScaler Software Monitoring, Clary & Inventory software, Prometheus, Grafana, Icinga, NVIDIA NSight
- Workload manager: Bull Slurm
- Orchestration: BlueBanquise, Ansible
- External Resource Access: NorduGrid ARC, dCache, CVMS
- Compute nodes Operating system: Red Hat Enterprise Linux 8
- Cloud/Service Virtualization: Proxmox, RHEV, oVirt
- Software stack: EasyBuild toolkit, Modules (Lmod)
- Compilers and SDKs: Intel Compilers (licensed Parallel Studio XE), TotalView (licensed), GCC, AMD Optimizing C/C++ Compiler, NVIDIA SDK
- MPI suites: OpenMPI, IntelMPI
- Programming languages: Python, Fortran, C/C++, R, Julia, Go, Scala
- Numerical, data and parallel/accelerator libraries: BLAS, LAPACK/ScaLAPACK, MKL, BLIS, FFTW, HDF5, netCDF, Eigen, ARPACK, CUDA, cuDNN, cuFFT, cuRAND, cuSOLVER, cuSPARSE, cuTENSOR, TensorRT, KOKKOS, Jarvis, DeepStream SDK, DALI, AmgX, NCCL, Intel TBB, nvGRAPH, Thrust, nvJPEG, NVIDIA Performance Primitives, Video Codec SDK, Optical Flow SDK.
- Frameworks: PyTorch, TensorFlow
- Containers: Singularity Pro, Docker
- Other: Remote GUI X11-forwarding, User licensed Matlab
Slurm partitions: The default partition is named cpu. Resource limits, node list, and memory information are presented in the following table:
HPC Vega documentation: https://doc.vega.izum.si
Application domains
There are several domains and applications where Slovenian experts and expert researchers have developed advanced approaches or are part of the development. In these domains, targeted high-level support or even co-development for substantial use of the infrastructure from user communities and projects in these spaces are foreseen. These domains and applications include:
- Machine learning, including container-based and optimised vector/GPU based application deployment for domain-specific systems as well as general frameworks (PyTorch, Theano, Caffe, Tensorflow) with optimizations for accelerator sharing, interconnect and RDMA architectural challenges, and new deployments.
- Biomolecular and materials simulations based on force-field molecular dynamics, with support for NAMD, Gromacs, Amber, and LAMMPS. Modelling of enzymatic reaction with techniques based on the empirical valence bond approach.
- Quantum chemistry and materials modelling and simulations with support for Gaussian, NWchem, ORCA, and VASP and other popular packages.
- Materials research with Large-scale Monte Carlo simulations of polymers, analysis of liquid crystal defects with Quantum ESPRESSO. Efforts in integration between machine learning, ab-initio models and Monte Carlo in progressive systems in high-energy physics, quantum chemistry, materials science, and complex matter research.
- Medical physics, fast, possibly on-line, GPU based analysis of medical tissues using RTE solution of layered media.
- Non-equilibrium quantum and statistical physics, dynamics and statistical properties of many-body system.
- Fluid dynamics simulations and analysis in reactor physics and technology, research and simulation in particle transport theory (neutrons, protons) with Singularity and Docker environments for Monte Carlo simulations for reactor physics of power reactors, research reactor physics, nuclear fusion, nuclear data evaluation and plasma physics.
- Astrophysics, data mining in large astrophysical collaboration datasets (Pierre Auger in Argentina and CTA), modelling of radiation from astrophysical structures. CORSIKA‑based simulation and analysis of high energy cosmic ray particle-initiated air showers.
- High-energy physics, extreme scale data processing, detector simulation, data reconstruction and distributed analysis, ATLAS at CERN, Belle2 experiment at KEK, Japan.
- Bioinformatics (Megamerge, Metamos), co-development and data-flow optimizations for human genomics (GATK, Picard) with many applications in human, animal and plant-based research, also in medicine and medical diagnostics.
- Fire-dynamics and simulations (FDS), fluid dynamics with OpenFOAM.
- Medical image processing and research work with medical image analysis and modelling in medical physics.
- Satellite images and astronomic image processing, GIS processing using modern scalable machine-learning approaches, basic parallel and message-passing programming with new architectures and interconnects, support for basic mathematical and computational libraries, including Octave, Sage, Scilab.
Collaboration across disciplines, software stacks, and system solutions has proven to be extremely effective cross-development and interdisciplinary work, especially in combinations with ICT-related disciplines, machine learning, data processing, cross-pollination of detailed modelling, Monte Carlo simulation and signal analysis, optimised modelling and machine learning model, with particular attention to introspective machine learning, in the stack of approaches to high energy physics, computation chemistry from quantum levels to protein folding and complex matter analysis and modelling.
Benchmarks
The procurement process if the Vega system relied on the following list of benchmarks for the evaluation of submitted tenders:
Synthetic benchmarks:
- Linktest
- IMB
- HPL
- HPCG
- STREAM
- IOR
- Mdtest
- Iperf3
- Firestarter
Application benchmarks:
- GROMACS
- Quantum ESPRESSO
- HEPSpec06
- OpenFOAM
- TensorFlow Resnet-50